Crowdsourcing applications addressing diseases and public health: a perspective on COVID-19 infestation
Mallick D.1, Datta U.2*
DOI: https://doi.org/10.17511/ijmrr.2021.i04.04
1 Debangshu Mallick, Researcher and Academician, Department of Computer Science and Engineering, The University of Calcutta (CU), Kolkata, West Bengal, India.
2* Upasana Datta, Advisory board member, Department of Research and Development, Uttoran Foundation, Kolkata, West Bengal, India.
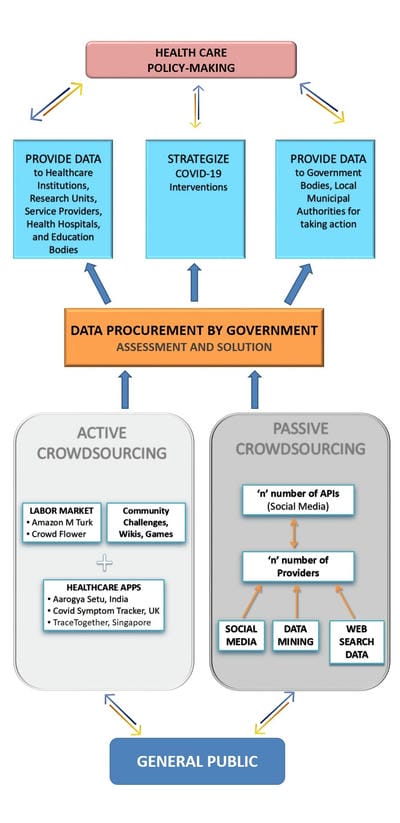
The spread of the COVID-19 disease with an unprecedented speed into humans, and the global scale of its occurrence over multiple geographic locations, since December 2019, in Wuhan, China, has sparked off extensive confusion and debate in public health, giving it the status of a pandemic. The inability of restraining the outbreak in the early stages, has multiplied the disease risk to fatal complications. Crowdsourcing technique can conglomerate crowd knowledge for solving problems revolutionizing health care by use of internet sources, data mining, e-health trackers, etc. to collect and assess data faster to the rate of spread of infection, directly from a point source (individual-level). The present study provides perspectives on crowdsourcing in alignment with health care and public health services by critically comparing strengths and challenges with traditional methods. For the same 3 models have been designed by the authors, for improvement in public health care, in the wake of the COVID-19 infestation.
Keywords: Crowdsourcing, Public health care, Infectious disease, Computational biology, COVID-19, Data mining, Health tracker apps, Pandemic
| Corresponding Author | How to Cite this Article | To Browse |
|---|---|---|
| , Advisory board member, Department of Research and Development, Uttoran Foundation, Kolkata, West Bengal, India. Email:  |
Mallick D, Datta U. Crowdsourcing applications addressing diseases and public health: a perspective on COVID-19 infestation. Int J Med Res Rev. 2021;9(4):225-234. Available From https://ijmrr.medresearch.in/index.php/ijmrr/article/view/1312 |
 |
 ©
©